
Streaming Data Services & Integration for Real-Time AI
To deliver real-time AI, you need streaming data services that connect sources, process events, and expose AI-ready outputs with enforcement of rights, privacy, and SLAs. This article outlines integration patterns, shows Spark Streaming Databricks examples, and explains how to choose streaming data solutions that scale securely.
Why Services (Not Just Pipelines)
A pipeline is code; a service is a contract: uptime, latency, schema, security, licensing, and observability. As your org connects more producers and consumers, those guarantees let teams ship faster and stay compliant.
Service qualities to demand
- Low, predictable latency (p95)
- SLOs & on-call for ingestion/processing/serving
- Schema contracts with versioning & deprecation policies
- Lineage & audit for every event
- Rights & consent metadata with enforceable policies
- Usage-based pricing and metering (especially for external consumers)
- Usage-based pricing and metering (especially for external consumers)
Integration Blueprint (Step-by-Step)
Pattern Catalog for Streaming Data Integration
- Event Sourcing + CDC: capture all state changes as append-only events.
- CQRS: separate write models from read models for fast queries.
- Enrichment at the edge: add geo, device, license, and consent near the source.
- Dual writes (with caution): only if transactional guarantees exist; otherwise stream-first.
- Zero-ETL to consumers: expose a governed streaming data service rather than raw tables.
- Zero-ETL to consumers: expose a governed streaming data service rather than raw tables.
Example: Spark Streaming Databricks for Real-Time Features
from pyspark.sql import functions as F, types as T
# Read from Kafka topic 'transactions'
tx = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers","broker:9092")
.option("subscribe","transactions")
.load())
# Parse JSON payload
df = (tx.selectExpr("CAST(value AS STRING) AS v")
.select(F.from_json("v", T.StringType()).alias("raw")))
# Assume a parsed schema function parse_tx(raw) -> structured columns
# (replace with from_json using a StructType in production)
# Example feature: rolling spend per user in 5m windows
features = (df
.withWatermark("event_time","15 minutes")
.groupBy(
"user_id",
F.window("event_time","5 minutes","1 minute")
)
.agg(F.sum("amount").alias("spend_5m"))
.select("user_id","window.start","window.end","spend_5m"))
(features.writeStream
.outputMode("append")
.format("delta")
.option("checkpointLocation","/chk/tx_features")
.start("/delta/features/spend_5m"))This demonstrates structured streaming databricks producing near-real-time features with watermarks and exactly-once writes to Delta.
Operational Guardrails
- Idempotency & dedupe: natural keys + sink upserts
- Retry strategy: exponential backoff with DLQs (dead-letter queues)
- Schema enforcement: contract tests in CI/CD; break builds on incompatible changes
- Secrets & auth: per-topic credentials and service accounts
- Regionalization: route EU data to EU processing to meet residency rules
- Cost hygiene: right-size clusters, auto-stop, tiered storage
- Cost hygiene: right-size clusters, auto-stop, tiered storage
Build vs. Buy: What’s Right for You?
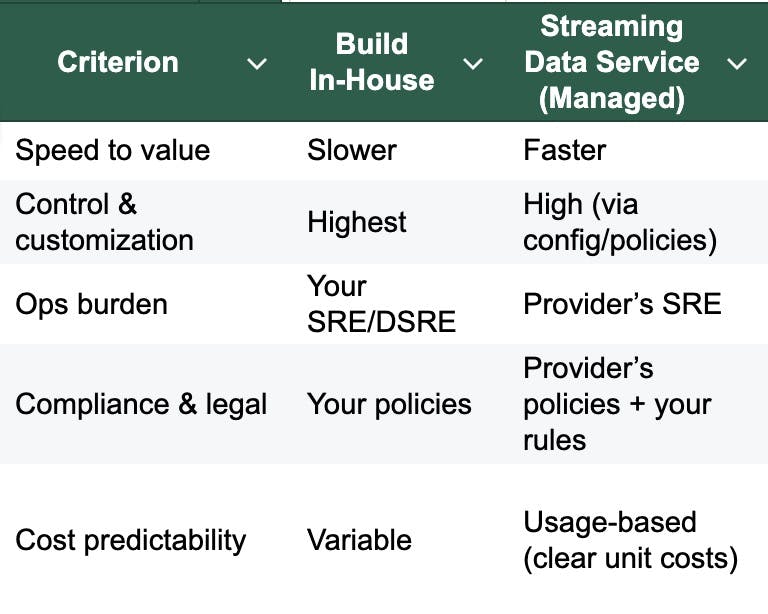
If your roadmap includes externalizing data (partners, ecosystem, or AI model providers), a managed streaming data service with licensing and metering is usually the safer path.
Selecting Streaming Data Solutions
- Latency & throughput meet your SLAs
- Databricks/Spark support if your team is SQL/Spark-first
- Contract-level governance (catalog, lineage, policy checks)
- Rights enforcement (consent, license, jurisdiction)
- Usage metering & billing for partner/AI consumption
- Replay & time travel for audits and ML backfills
- Security: encryption, scoped tokens, private networking
- Security: encryption, scoped tokens, private networking
How Alien Intelligence Fits In
Alien Intelligence is the rightful data streaming infrastructure for the AI industry.
We connect high-quality content with AI systems that value accuracy, context, and fairness.
- AI-ready: curated, structured, rights-cleared
- Streaming-first: delivered in real time, as endpoints
- Rights-built-in: every stream enforces usage, consent, and compliance
- Rights-built-in: every stream enforces usage, consent, and compliance
Build AI that isn’t just powerful — but trustworthy, lawful, and future-proof.
→ Book a demo or download the white paper to see rights-first streaming in action.
FAQs
What is a streaming data service?
A managed, governed interface to real-time event flows with SLAs, contracts (schema, latency), and policy enforcement.
How does streaming data integration differ from batch integration?
It connects systems continuously with event-time semantics, backpressure, and always-on jobs—no nightly windows.
Can I use Databricks for both batch and streaming?
Yes. Spark Structured Streaming unifies batch and streaming logic and integrates tightly with the Databricks lakehouse.