
Streaming Data Analytics: Tools, Architecture & Best Practices
Streaming data analytics turns continuous event streams into immediate insights using a pipeline of ingestion (Kafka), processing (Spark/Flink), storage (lakehouse/OLAP), and serving (APIs/dashboards/AI). Success depends on robust streaming data architecture, governance, and cost control.
1) What Is Streaming Data Analytics?
It’s the discipline of transforming streaming data into metrics, features, and decisions as the data arrives. Instead of waiting for a daily job, you compute windows, joins, and models in motion to support real time streaming data analytics—alerts, recommendations, and live KPIs.
Why It’s Different from Traditional BI
- Latency: sub-second to minutes, not hours
- Semantics: event-time windows, late data, stateful operators
- Operations: always-on jobs, checkpointing, backpressure handling
- Operations: always-on jobs, checkpointing, backpressure handling
2) A Reference Streaming Data Architecture
Sources → Ingestion → Processing → Storage → Serving → Governance
- Sources: apps, devices, logs, payments
- Ingestion (Transport): Kafka/Pulsar/Kinesis with partitions & retention
- Processing: Spark Structured Streaming, Flink, Kafka Streams (stateful, exactly-once, watermarks)
- Storage: lakehouse (Parquet/Delta/Iceberg), OLAP DB, feature store, vector DB
- Serving: dashboards, alerting, APIs, ML inferences
- Governance & Security: schemas, lineage, catalog, PII policy, licensing/consent
- Governance & Security: schemas, lineage, catalog, PII policy, licensing/consent
Design principles
- Event time first (use watermarks)
- Idempotent sinks (avoid duplicates)
- Schema contracts (evolve safely)
- Isolation & backpressure (protect sinks)
- Observability end-to-end (traces, metrics, logs)
- Observability end-to-end (traces, metrics, logs)
3) Streaming Data Analytics Tools (Pros & Fit)
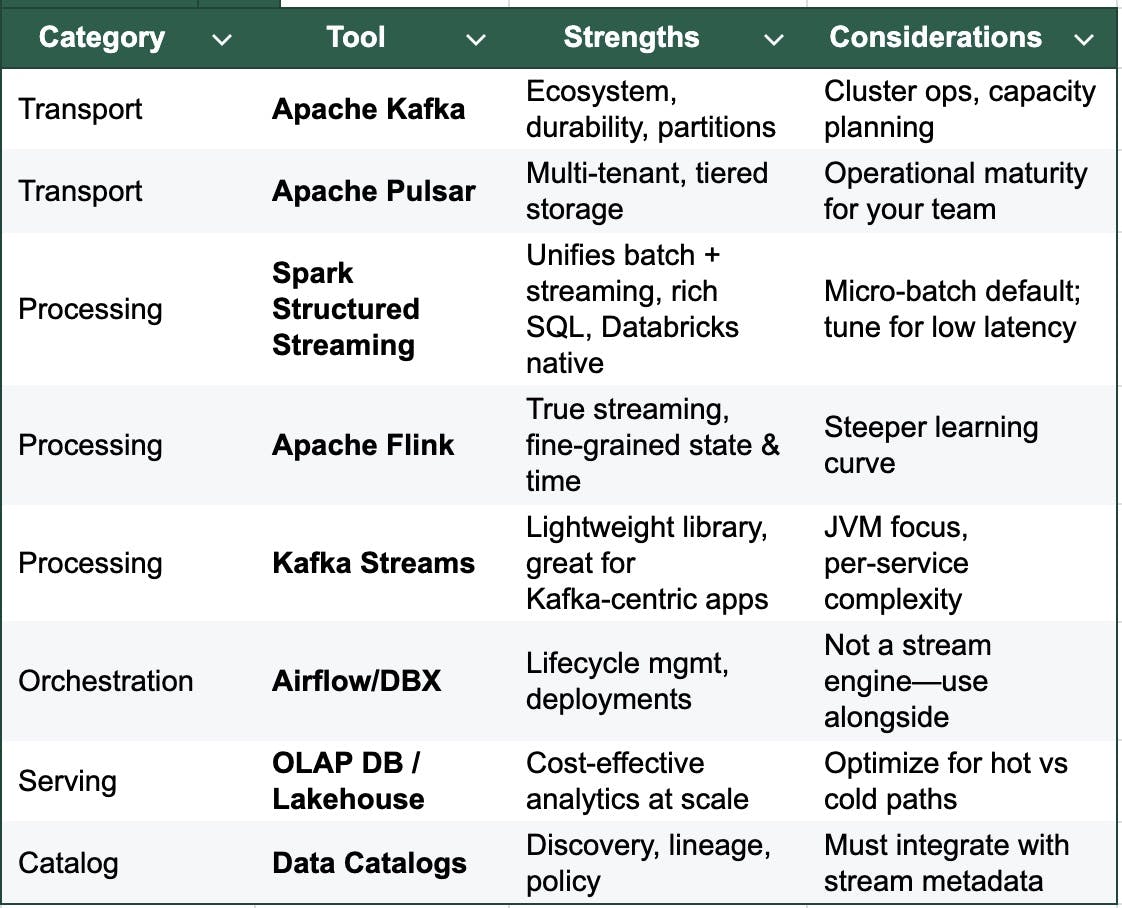
Looking for a managed path? Databricks offers Structured Streaming with native lakehouse integration and production-grade ops.
4) Real-Time Analytics Patterns
- Sliding/Tumbling windows: rolling KPIs, rate limits
- Sessionization: group user actions into sessions
- Stream-stream joins: enrich events with other streams
- Stream-table joins: augment with reference data (dimensions/features)
- CEP (complex event processing): detect sequences/anomalies
- Lambda & Kappa: hybrid batch+stream vs stream-only designs
- Lambda & Kappa: hybrid batch+stream vs stream-only designs
5) Best Practices (Battle-Tested)
- Model your events with a stable key and semantic timestamps.
- Choose partitions by access patterns; avoid hot keys.
- Use watermarks to bound late data while staying correct.
- Exactly-once at the edges: idempotent sinks, transactional writes.
- Backpressure & autoscaling: match consumer speed to producer spikes.
- Data quality in motion: schema validation, field constraints, PII scanning.
- Observability: p95/p99 latency, throughput, lag, error budgets.
- Cost controls: retention tiers, compaction, sampling where acceptable.
- Rights & compliance: attach license/consent context to each event; enforce at consumption.
- Chaos & recovery drills: test checkpoint restore and failover.
- Chaos & recovery drills: test checkpoint restore and failover.
6) Example: Streaming Analytics with Spark Structured Streaming (Databricks)
SQL (auto loader + aggregate)
-- In Databricks SQL
CREATE OR REPLACE STREAMING LIVE TABLE pageviews_raw
AS SELECT * FROM cloud_files("s3://events/pageviews/", "json");
CREATE OR REPLACE STREAMING LIVE TABLE pageviews_1m
AS SELECT
user_id,
window(event_time, "1 minute") AS win,
COUNT(*) AS views
FROM STREAM pageviews_raw
GROUP BY user_id, window(event_time, "1 minute");
PySpark (event-time windows with watermark)
from pyspark.sql import functions as F
events = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers","broker:9092")
.option("subscribe","pageviews")
.load()
)
json = events.selectExpr("CAST(value AS STRING) AS json")
df = spark.read.json(json.rdd.map(lambda r: r.json))
metrics = (df
.withWatermark("event_time","10 minutes")
.groupBy(
F.window("event_time","1 minute","30 seconds"),
"user_id"
)
.agg(F.count("*").alias("views"))
)
query = (metrics.writeStream
.outputMode("append")
.format("delta")
.option("checkpointLocation","/chk/pageviews")
.start("/delta/pageviews_1m"))
This pattern demonstrates structured streaming databricks using event-time windows, watermarks, and exactly-once sinks (Delta).
7) Choosing the Right Streaming Data Solutions
- Latency target? Sub-second vs seconds/minutes determines engine and config.
- Peak throughput? Plan partitions, state size, and checkpoint IO.
- Team skills? Spark SQL familiarity vs Flink’s APIs.
- Governance? Built-in lineage, schema registry, policy enforcement.
- Rights & revenue? If events carry licensed content/usage, choose a streaming data service that enforces it.
- Rights & revenue? If events carry licensed content/usage, choose a streaming data service that enforces it.
How Alien Intelligence Fits In
Alien Intelligence is the rightful data streaming infrastructure for the AI industry.
We connect high-quality content with AI systems that value accuracy, context, and fairness.
- AI-ready: curated, structured, rights-cleared
- Streaming-first: delivered in real time, as endpoints
- Rights-built-in: every stream enforces usage, consent, and compliance
Build AI that isn’t just powerful — but trustworthy, lawful, and future-proof.
Talk to us about your real-time targets and compliance requirements.
FAQs
What is real time streaming data analytics?
Analytics performed as events arrive, producing immediate metrics, alerts, and model features.
Which streaming data analytics tools should I start with?
If your team knows Spark/SQL, start with Spark Structured Streaming on Databricks; otherwise evaluate Flink for ultra-low latency and complex state.
How do I keep costs under control?
Autoscale consumers, separate hot vs cold paths, tune retention, and monitor lag and checkpoint IO.